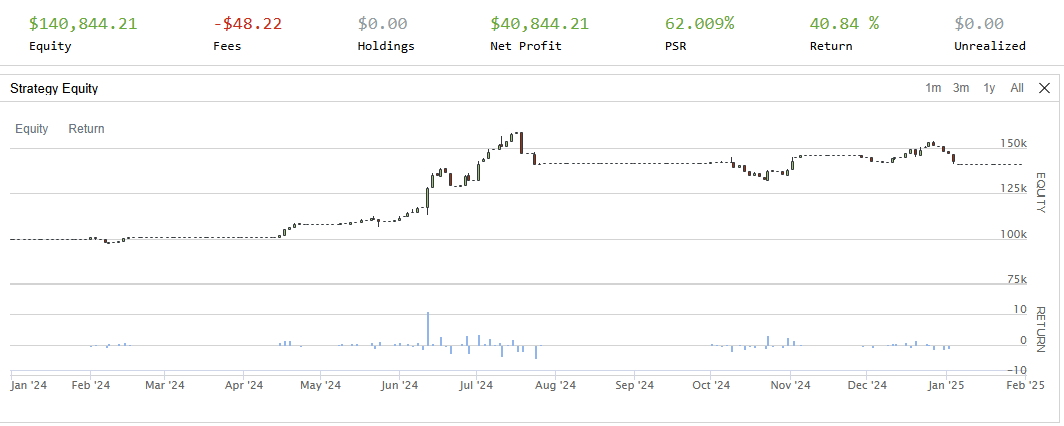
从Devops到MLOps再到LLMOps
由ChatGPT翻译自原网址 从 CI/CD 开始网上有很多关于 CI/CD(持续集成/持续交付)的定义,但其实所有和 XXXOps 相关的东西,都是基于 CI/CD 的。 在我的理解中,CI/CD 是一种开发和运维的实践,通过自动化构建、测试和部署流程,提升软件交付的效率和质量。 举个例子,想象你平时是怎么用 GitHub 和 Docker 的。当你把代码提交到远程仓库,代码会被自动编译、构建并测试,这些过程就属于 CI。而当你把代码部署到测试环境,最后上线到生产环境,这些步骤就属于 CD。 换句话说: CI(持续集成): 专注于代码的构建和测试,确保代码改动能够可靠地集成。 CD(持续交付): 专注于部署,确保代码能顺利从测试环境交付到生产环境。 由此可以看出,DevOps(开发和运维)本质上就是 CI/CD 流程的具体实现,让软件工程师的工作更简单高效。 MLOps:比 DevOps 更进一步MLOps 包含了 DevOps 的所有概念,但它的扩展范围还包括对数据、模型训练、分析和部署的管理。 此时,你可...
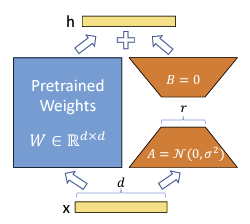
LoRA微调Twitter-roBERTa-base for Sentiment Analysis
这两天在准备一些简历和面试的东西,终于也是要迈出求职的这一步了。美国我是打算放弃了,主要感觉还是经历太少了,简历就看着没人家炫酷。也罢,回国吃烧烤也很香。 前两天面试了百度的NLP算法实习生,感觉是寄了,因为是个日常实习,也没办法中途回国。不过面试的时候提到了上学期做的一个小项目,就是用Hugging Face上的模型做情感分析,也谈到了微调。 0. 前戏:LoRALoRA, 全名Low-Rank Adaptation of Large Language Models,在2021的某个夏天,在一伙微(巨)软(硬)的研究员疯狂玩弄线性代数后,LoRA横空出世。 死去的线代知识准备发起攻击了! Rank这个概念在我们小学二年级的时候就学过,指的是矩阵的秩,行向量或列向量中最大线性无关组的向量数量。可以理解为矩阵里真正包含信息的行数。 例如: \begin{pmatrix} 1 & 0 & 1 \\ 0 & 1 & 1 \\ 0 & 2 & 2 \\ \end{pmatrix} 是一个秩为2的矩阵,因为第二行和第三行是一样的。 \beg...

新时代八股
仅用来记录一些面经。 中心极限定理(Central Limit Theorem, CLT)是统计学中的一个重要定理,它说明了在适当的条件下,大量独立同分布的随机变量之和的分布接近正态分布。这个定理有两个重要的内容和条件: 内容:当样本量足够大时(通常n≥30),无论原始总体分布是什么,样本均值的分布都趋近于正态分布。这意味着,我们可以利用正态分布的性质来估计均值的概率,进行假设检验等。 条件:中心极限定理适用的条件包括样本是随机的、样本之间相互独立、样本来自同一总体或分布、样本大小足够大(n≥30通常被认为是足够的,但对于非常偏斜的分布,可能需要更大的样本量)。 Z检验和t检验的差别,以及为什么小样本用t检验: Z检验用于样本量大(n>30)且总体标准差已知的情况,依据的是正态分布。 t检验用于样本量小(n≤30)或总体标准差未知的情况,依据的是t分布。t分布与正态分布相似,但是在尾部更为厚重,以适应小样本情况下估计的不确定性更大的问题。 小样本使用t检验的原因:当样本量小且总体标准差未知时,使用样本标准差来估计总体标准差,会引入额外的不确定性。t分布考虑了这种不确定...

超参数优化
调参在训练模型的过程中,为了达到更好的结果,免不了要优化超参数,又称调参。虽然感觉提升并不显著,但提高一点算一点嘛。 在Amazon介绍的超参数调优的介绍中,在传统的机器学习中一般有三种调优方式(其实就两种,网格搜索和随机搜索没什么区别): 网格搜索(Grid search) 随机搜索(Random search) 贝叶斯优化(Bayesian optimization): 为了演示,这里使用Random Forest Classifier。 0. 数据随机在kaggle上找了个Dry Bean数据集, 我也没仔细看具体是什么,大概就是不同豆子的种类吧,应该和iris差不多。 import numpy as np import pandas as pd from sklearn.metrics import confusion_matrix, classification_report, accuracy_score from sklearn.model_selection import train_test_split from sklearn.ensemble impor...

简单NLP — 情感分析
前几天面试的时候,面试官突然问我“为什么想选择数据科学相关的专业?” 一时语塞,说我纯粹的热爱吧好像又有些虚伪,无非就是为了混口饭吃,哪有什么宏大叙事和美好愿景。 但是,我这样回答面试官的:我说也许在我们不知道的情况下,一些简单的数据分析能给我们带来很多信息,这些信息可以是商业上的,也可以是社会上的,甚至可以是个人的。因为我有每天记日记的习惯(虽然大部分是在写废话。。。),然后前几天刚好用Hugging Face上开源的模型简单跑了一遍对每天日记的情感分析。我回答面试官,大概,数据分析也能让我更好的认识自己吧。 所以开一个“简单”系列,就是无脑调包就好了,没什么技术含量。 0, 我的日记 这是我记日记的习惯,写一些话,然后没有标点符号(亏贼这太变态了),靠换行来断句。在python里,数据大概长这样: 我要的其实就是diary_item_content里的内容,一顿操作后提取内容,在简单做点预处理准备分析。(此处无码,因为每个人写日记的习惯都不一样罢。) 1, 直接调用在线模型1.1 Hugging Face在Hugging Face,有众多深度模型可供选择。可以用来微调也可...

Hexo基础进阶设置,2024版
在上篇我们搭建了一个很基础的网站,这次来看看我个人有哪些在2024年要做的配置吧。 事实上,在原文档,以及博主lijunliang的文章里已经有了非常详细的说明,想必也比我这个门外汉再写一份来的更清晰易懂。 但是这些文章也许有些年头了,有些地方在2024年可能需要额外的配置,这篇文章会简单介绍我做的改动。 1,代码块highlight在原文说明highlight代码块的地方,原文如下 Starting from Hexo 5.0.0 version, it comes with support for prismjs code syntax highlighting, and hexo-theme-matery has been modified to support it. If the plugin of hexo-prism-plugin has been installed in your blog, then you need to execute npm uninstall hexo-prism-plugin to uninstall it, otherwise ...
Hexo + Github个人网页制作
作为第一篇文章,就讲讲这个网站是怎么做的吧。 很早就有想做一个个人网站了,但是无奈不会的太多也就打消了这个念头。不然还得从头学一些奇奇怪怪的JavaScript和CSS相关的东西,这对我来说可就太折磨了。但是,昨天聊天时朋友提了一嘴:“你们没有个人作品集之类的东西吗?”, 我说还真没有,但是又突然想到了个人网站这种东西。想起本科时那些教授都有自己的网站,我就又去搜索了一下类似于“个人网站制作”的内容。 没想到居然有现成的库可以直接用,那就是Hexo了,甚至还配有各种主题(theme)。时过境迁,现在一切都变得那么容易,都可以一键生成。 跟我说,谢谢你,开源侠。 第一步:配置Github使用Github的原因很简单,对于个人用户它提供一个免费的user page,完全可以当个人网页用。 注册Github此步略过 本地生成id_rsa和id_rsa.pub打开一个CMD终端(或者windows下推荐使用Powershell),依次输入 git config --global user.name "Github用户名" git config --global u...